Memory alignment of doubles in C#
A while ago, I mentioned on Twitter an interesting quirk of objects in .NET: when running in 64 bits, objects are aligned on a 8-bytes boundary despite having a 32 bits header, and therefore 32 bits are “lost” before each object:
It bothers me so much that on #dotnet on 64-bit, 4 bytes are wasted for *every class instance* because objects are aligned on a 8 bytes boundary and the header has a fixed size of 4 bytes. pic.twitter.com/kToB6rnABG
— Kevin Gosse (@KooKiz) August 19, 2023
And then, Egor Bogatov replied with a funny bit of trivia about how arrays of doubles are aligned using a fake object:
The funny case is how it's implemnted for a normal heaps (not LOH) on x86: if we have, say, double[100] and current GC's allocator is only 4-bytes aligned - we allocate a fake object of variable size to make next object 8-bytes aligned :)
— EgorBo (@EgorBo) August 19, 2023
It really got my attention and I spent the next few days digging into how arrays of doubles are aligned in .NET, and today I’m taking you down with me.
The cost of unaligned doubles
The first question to answer is: why should we align doubles at all? And the answer is… well, I’m not sure. Please take the next few paragraphs with a pinch of salt: I’m no expert in that domain, and it’s only information I’ve gathered from various articles or online discussions.
From what I’ve read, it’s a combination of two factors:
-
On older x86–64 CPUs, accessing unaligned data had a significant performance penalty. Apparently that’s hardly the case anymore, Intel and AMD did a fine job bringing that cost down to zero or close to zero. Maybe that’s still the case on other architectures, I don’t know.
-
If doubles are not aligned on 8-byte boundaries, there is a risk that they may span two cache lines, leading to less efficient memory access.
Overall, the consensus seems to be that it used to be bad, but today not so much.
I decided to see by myself, and wrote a benchmark to try and measure the cost of unaligned memory access with doubles.
public unsafe class DoublesBenchmark
{
private static readonly void* Memory;
private const int Count = 10_000;
[Params(0, 4, 8, 12, 16)]
public int Offset { get; set; }
static DoublesBenchmark()
{
Memory = NativeMemory.AlignedAlloc(Count * sizeof(double) + 32, 8);
}
[Benchmark]
public double Sum()
{
var doubles = new Span<double>((byte*)Memory + Offset, Count);
double result = 0;
foreach (var value in doubles)
{
result += value;
}
return result;
}
The idea is to allocate a chunk of native memory (aligned on an 8 bytes boundary), then interpret it as a sequence of doubles starting at a variable offset.
// * Summary *
BenchmarkDotNet v0.13.7, Windows 10 (10.0.19045.3448/22H2/2022Update)
Intel Core i7-5820K CPU 3.30GHz (Broadwell), 1 CPU, 12 logical and 6 physical cores
.NET SDK 8.0.100-rc.1.23463.5
[Host] : .NET 8.0.0 (8.0.23.41904), X86 RyuJIT AVX2
Job=InProcess Toolchain=InProcessEmitToolchain
| Method | Offset | Mean | Error | StdDev |
|------- |------- |---------:|----------:|----------:|
| Sum | 0 | 8.774 us | 0.0324 us | 0.0288 us |
| Sum | 4 | 8.981 us | 0.0449 us | 0.0398 us |
| Sum | 8 | 8.789 us | 0.0457 us | 0.0427 us |
| Sum | 12 | 8.969 us | 0.0597 us | 0.0559 us |
| Sum | 16 | 8.780 us | 0.0371 us | 0.0347 us |
We can see that the mean execution time is higher by about 2% when the doubles are aligned on a 4-bytes boundary (offsets 4 and 12), compared to the 8-bytes boundary (offsets 0, 8, and 16). This is hardly the end of the world, but that’s still significant. I’ve tried many variations of the benchmark (including with random access instead of sequential) and always find a difference of about 2%.
Alignment of arrays of doubles in .NET
Now that we have empirical evidence of the benefits of aligning doubles, let’s see what the .NET runtime does about that. When running in 64-bit, all objects are aligned on a 8-bytes boundary, so there’s nothing special to do about doubles. But what if the application is running in 32-bit?
There is a special mechanism to lower the LOH threshold for arrays of double. The LOH is aligned on 8 bytes even when running in 32-bit, so allocating the arrays of double there is a way of ensuring that they’re properly aligned. See the following code:
Console.WriteLine(GC.GetGeneration(new double[999])); // 0
Console.WriteLine(GC.GetGeneration(new double[1000])); // 2
If an array of double has at least 1000 elements, it gets allocated in the LOH, despite being much smaller than the 85,000 bytes threshold. That number can be tweaked using theDOTNET_DoubleArrayToLargeObjectHeap environment variable.
For instance, if I set DOTNET_DoubleArrayToLargeObjectHeap to 0, then all arrays of doubles are allocated in the LOH, regardless of size:
Console.WriteLine(GC.GetGeneration(new double[0])); // 2
Console.WriteLine(GC.GetGeneration(new double[1])); // 2
Great. But what about arrays that have fewer elements than the DoubleArrayToLargeObjectHeap threshold? A quick test shows that they are still aligned on 8 bytes, despite not being allocated in the LOH:
static bool IsAligned(object obj) => ((nint)(&obj) & 0x7) == 0;
for (int i = 0; i < 10; i++)
{
var array = new double[2];
Console.WriteLine(GC.GetGeneration(array)); // 0
Console.WriteLine(IsAligned(array)); // true
}
This article could stop here, but as hinted at the beginning, there is an interesting hack involved under the hood to force that alignment.
Filling in the blanks
To understand what happens, you must first learn about the allocation context. Nowadays, applications are massively multithreaded, and if each thread needed to talk to the GC every time they allocate an object, it would cause a lot of contention. Instead, every thread is given a personal allowance, a segment of zero’d memory that they can use as needed. Every time the code tries to allocate a new reference object, the thread tries to use the memory from its allocation context. When there is no room left, the thread asks ̶m̶o̶m̶m̶y̶ the GC for a new allocation context. When the GC is out of memory to give (or when it judges that it has given too much memory already), a garbage collection is triggered.
In practice, the allocation context is a structure that contains, among other things, a pointer to the beginning of its allotted memory (in the alloc_ptr field) and a pointer to the end of that memory (in the alloc_limit field).
Two completely different code paths are used depending on whether there’s room left in the allocation context (fast path) or the thread has to ask for more (slow path). We’re going to see what happens in both.
The fast path
The fast path is in fact multiple paths. Specialized allocation methods are emitted for specific cases, and written in assembly code. And there are many of them:
CORINFO_HELP_NEWFAST,
CORINFO_HELP_NEWFAST_MAYBEFROZEN, // allocator for objects that *might* allocate them on a frozen segment
CORINFO_HELP_NEWSFAST, // allocator for small, non-finalizer, non-array object
CORINFO_HELP_NEWSFAST_FINALIZE, // allocator for small, finalizable, non-array object
CORINFO_HELP_NEWSFAST_ALIGN8, // allocator for small, non-finalizer, non-array object, 8 byte aligned
CORINFO_HELP_NEWSFAST_ALIGN8_VC,// allocator for small, value class, 8 byte aligned
CORINFO_HELP_NEWSFAST_ALIGN8_FINALIZE, // allocator for small, finalizable, non-array object, 8 byte aligned
CORINFO_HELP_NEW_MDARR,// multi-dim array helper for arrays Rank != 1 (with or without lower bounds - dimensions passed in as unmanaged array)
CORINFO_HELP_NEW_MDARR_RARE,// rare multi-dim array helper (Rank == 1)
CORINFO_HELP_NEWARR_1_DIRECT, // helper for any one dimensional array creation
CORINFO_HELP_NEWARR_1_MAYBEFROZEN, // allocator for arrays that *might* allocate them on a frozen segment
CORINFO_HELP_NEWARR_1_OBJ, // optimized 1-D object arrays
CORINFO_HELP_NEWARR_1_VC, // optimized 1-D value class arrays
CORINFO_HELP_NEWARR_1_ALIGN8, // like VC, but aligns the array start
The one we’re going to focus on is CORINFO_HELP_NEWARR_1_ALIGN8, used for 1-dimensional arrays that need to be aligned on an 8 byte boundary. In other words, the one used when allocating an instance of double[].
On x86, those helpers are emitted by a C++ method that generates assembly code depending on a set of conditions.
Before digging in, let’s take a minute to think about what that allocation code should look like. Remember, we’re focusing on the case of a 32-bit process.
Every heap allocation has a size that is a multiple of the pointer size. Even if you’re feeling playful and box a struct of 13 bytes, it will be padded to 16 bytes (and will occupy a total of 24 bytes in memory because of the header and the method-table pointer). Because of this, we know that the allocation pointer (the pointer in the allocation context that indicates where the available zero’d memory starts) is always aligned on 4 bytes.
Then one of two thing should happen:
-
Either we’re lucky and the allocation pointer is also aligned on 8 bytes (since 8 is the smallest multiple of 4, it should happen fairly often), then we can directly allocate the array. Allocating the array means bumping the value of the allocation pointer by the size of the array, then returning the old value.
-
Or the allocation pointer is not properly aligned, in which case we should bump it by 4 bytes before allocating the array.
In practice, this is not what happens:
-
In the lucky case, when the allocation pointer is aligned on 8 bytes, then no surprise: the array is directly allocated as expected.
-
In the unlucky case, the allocation pointer is bumped by 12 bytes (instead of just 4). Those 12 bytes are used to allocate an instance of
Object. Following that allocation, the allocation pointer is correctly aligned (4 + 12 = 16, which is a multiple of 8) so the array can be allocated.
You may be wondering why 12 bytes for an Object. In .NET, because of some requirements dictated by the GC, heap allocations can’t be smaller than 3 pointers. So even a simple Object will use 12 bytes on 32-bit, and 24 bytes on 64-bit.
But then comes the real puzzle: why allocating an actual object instead of just bumping the allocation pointer by 4? It’s 8 extra bytes that are apparently wasted? I don’t know what the official reason is, but I see at least one scenario that would be problematic if we just left an empty gap in memory: scanning the heap.
How to scan the heap
Scanning the heap is usually done by the GC, but can also be done by debugging tools (for instance, the !dumpheap command in Windbg/dotnet-dump). Objects are not indexed, there is no central repository you can read to know where each object is located. Instead, you need to read the raw memory and figure out what is an object and what is not.
First you need to know where the managed heaps start and end. Fortunately there are structures in memory for that. Then you assume that the heap starts with an allocated object, and read it’s method table. The method table contains a “base size” field, that tells you how big the object is in memory. From there, you can simply jump that amount of bytes in memory to find the next object and read its method table, and so on (of course it’s simplified, for instance arrays have a variable size).
This is all nice, but it assumes that objects are neatly packed in memory. What about the “holes” left by the GC when memory is fragmented? They’re actually filled with instances of a special object, Free, which has a variable size just like an array. You can actually see them when running the !dumpheap command in Windbg:
0:000> !dumpheap
Address MT Size
05831000 03109810 12 Free
0583100c 03109810 12 Free
05831018 03109810 12 Free
05831024 211e92e0 12
05831030 211e9648 20
05831044 05565ee0 12
05831050 211ac80c 32
06831000 03109810 12 Free
0683100c 03109810 12 Free
06831018 03109810 12 Free
07831000 03109810 12 Free
0783100c 03109810 12 Free
07831018 1f393bf0 44
07831044 1f3903fc 24
0783105c 1f393c94 24
07831074 1f36a8d0 56
The pseudo-code to scan the heap would look like this:
function scan_heap(start, end)
{
current = start;
while (current < end)
{
mt = *current;
if (mt == free_mt)
{
print "Found free object";
}
else
{
print "Found object of type " + GetObjectName(mt);
}
// Simplified. For arrays, we would also need to consider their length
current += mt->base_size;
}
}
With this knowledge, it becomes apparent why we can’t just bump the allocation pointer by 4 bytes. We would end up with 4 bytes of garbage and we wouldn’t know where to read next (though, if the empty memory is zero’d, I suppose we could just read everything until we find something that is not zero). Instead, we need to fill the gap with an object, so we can use its base size to find where the next “real” object starts.
There’s still one peculiar unexplained point: why does the fast path allocate an actual Object instead of the special Free object? And the answer is… I don’t know. I’ve thought long and hard about it, and couldn’t come up with a satisfying reason. Especially because, when moving the objects in memory, the GC does use instances of Free to align them. Why isn’t the allocator doing the same? I have no clue.
Locating the dummy object
Wouldn’t it be “fun” if we could actually observe that dummy object? First, we can observe it directly from the memory view of the debugger.
To do so, we need a way to make sure the allocation pointer is not aligned on 8 bytes. The allocation pointer is stored on the native Thread object, and we can retrieve it by using some deliciously unsafe C# code.
We start by declaring a helper method to retrieve a pointer to the native thread, using the private _DONT_USE_InternalThread field (rather than reflection, we use the brand new .NET 8 UnsafeAccessor to access it). We interpret its contents using Thread_data and gc_alloc_context structs that mimic the layout of their native counterparts.
static unsafe ref Thread_data GetCurrentNativeThread()
{
var currentNativeThread = GetNativeThread(Thread.CurrentThread);
return ref Unsafe.AsRef<Thread_data>((void*)currentNativeThread);
}
[UnsafeAccessor(UnsafeAccessorKind.Field, Name = "_DONT_USE_InternalThread")]
static extern ref IntPtr GetNativeThread(Thread thread);
[StructLayout(LayoutKind.Sequential)]
unsafe struct Thread_data
{
public nint vtable;
public int m_state;
public int m_fPreemptiveGCDisabled;
public nint m_pFrame;
public nint m_pDomain;
public int m_ThreadId;
public nint m_pHead;
public LockEntry m_embeddedEntry;
public nint m_pBlockingLock;
public gc_alloc_context m_alloc_context;
public nint m_thAllocContextObj;
public nint m_pTEB;
}
[StructLayout(LayoutKind.Sequential)]
unsafe struct gc_alloc_context
{
public nint alloc_ptr;
public nint alloc_limit;
public long alloc_bytes;
public long alloc_bytes_uoh;
public nint gc_reserved_1;
public nint gc_reserved_2;
public int alloc_count;
}
With those helper methods, we retrieve the allocation context and check whether the next allocation is going to be aligned on 8 bytes. If yes, then we box an int to offset the allocation pointer by 12 bytes (remember, 12 bytes is the minimum size of objects on the heap). Then we allocate our array of doubles. We print the address of the array, along with the method-table pointer of double[] and Object to help interpret the raw memory.
static bool IsAligned(nint address)
{
return (address & 0x7) == 0;
}
static unsafe nint GetAddress(object obj)
{
return (nint)(*(object**)&obj);
}
static unsafe void Main()
{
Console.WriteLine($"Object MT: {typeof(object).TypeHandle.Value:x2}");
Console.WriteLine($"Double[] MT: {typeof(double[]).TypeHandle.Value:x2}");
ref var allocContext = ref GetCurrentNativeThread().m_alloc_context;
object padding = null;
if (IsAligned(allocContext.alloc_ptr))
{
padding = (object)0xFFFFFFFF;
}
var array = new double[2];
Console.WriteLine($"Array address: {GetAddress(array):x2}");
// Add a breakpoint here
Console.ReadLine();
GC.KeepAlive(padding);
GC.KeepAlive(array);
We can see the result of the execution in the console:
Object MT: 5035ee0
Double[] MT: 2119ce70
Array address: 759c0a0
And the raw memory:
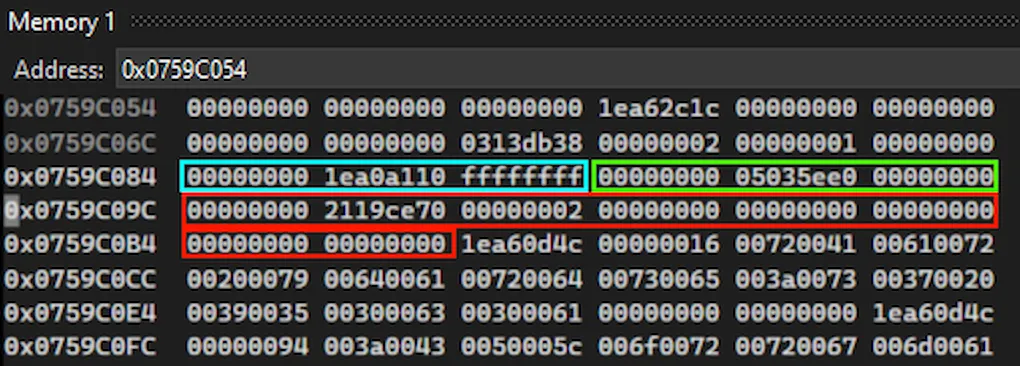
In blue, we can see the boxed int used for padding (recognizable by the value 0xffffffff). In red, we see the array of doubles (an empty header, the method-table pointer 2119ce70, the number of elements 2, then two empty doubles). And in-between, we see the dummy object inserted by the allocator, in green.
Now that’s we’ve “seen” the dummy object, let’s push things one step further: can we actually retrieve a reference to it?
static unsafe void Main()
{
var objectMT = typeof(object).TypeHandle.Value;
ref var allocContext = ref GetCurrentNativeThread().m_alloc_context;
object padding = null;
if (IsAligned(allocContext.alloc_ptr))
{
padding = (object)0xFFFFFFFF;
}
var array = new double[2];
var address = GetAddress(array);
var dummyObjectAddress = address - 12;
if (*(nint*)dummyObjectAddress == objectMT)
{
object dummyObject = *(object*)&dummyObjectAddress;
Console.WriteLine($"Found: {dummyObject}");
}
else
{
Console.WriteLine("The dummy object wasn't found :(");
}
}
And sure enough, the program will display in the console:
Found: System.Object
The slow path
There’s another peculiarity in the allocator code, this time in the slow path. The slow path is executed whenever there is not enough room left in the allocation context for the current allocation. The thread then has to ask the heap allocator for the needed amount of memory. The heap allocator returns a pointer to a chunk of memory of the desired size, and grants a new allocation context to the thread as a side-effect.
But the heap allocator has no API to return memory aligned on an 8-byte boundary, so more tricks are used. Instead of asking for the amount of memory needed for the array, the thread asks for that amount + 12 bytes. If the returned address is not aligned, then a dummy object is stored in the first 12 bytes, and the array in the remainder. But if the returned address is already aligned, then the thread stores the array and then… ends up with 12 bytes of unused memory. We’ve already seen that we can’t leave empty memory, so a dummy object is stored in the leftover.
In the fast path, we ended up with a dummy object whenever the address was not aligned, which sort of made sense… But in the slow path, we end up with a dummy object no matter what! Why not just ask for the size needed for the array, then ask for another extra 12 bytes only if the address is not aligned? Well, simply because when called, the heap allocator might decide to rebalance the heaps or trigger a garbage collection, so there is no guarantee that those 12 bytes will be contiguous with the memory previously returned.
Let’s update our program to test this behavior. It’s slightly more complex because we need to make sure that our array of double exceeds the size left in the allocation context. To compute the size left, we substract the pointer to the end of the allocation context (alloc_limit) from the pointer to the beginning of the allocation context (alloc_ptr). There’s one subtlety though: we need to make sure that there isn’t too much space available in the allocation context to begin with. If there are more than 8000 bytes available, then we will need to allocate an array of more than 1000 elements. And as we’ve seen previously, those get allocated directly in the LOH, so the allocation context won’t be used. To prevent that, we first allocate an array of bytes big enough to leave only ~500 bytes in the allocation context.
With that in mind, let’s write a FindDummyObject method, that tries to locate the dummy object after allocating an array of double. The method takes one parameter, indicating whether the allocation context pointer should be initially aligned or not.
static unsafe void FindDummyObject(bool alignArray)
{
var objectMT = typeof(object).TypeHandle.Value;
// Minimize the probability of having a collection during the scenario
GC.Collect();
var bag = new List<object>(10);
ref var allocContext = ref GetCurrentNativeThread().m_alloc_context;
var budget = allocContext.alloc_limit - allocContext.alloc_ptr;
if (budget > sizeof(double) * 1000)
{
// If there's too much budget left, we'll end up allocating an array of more than 1000 elements
// which will be allocated in the large object heap, and we won't be able to find the dummy object
bag.Add(new byte[budget - 500]);
budget = allocContext.alloc_limit - allocContext.alloc_ptr;
}
if (IsAligned(allocContext.alloc_ptr) != alignArray)
{
// Allocate 12 bytes to change the alignment
bag.Add((object)0xFFFFFFFF);
}
var length = budget / sizeof(double) + 10 /* add a few elements just to be sure */;
var array = new double[length];
// Now try to find the dummy object
var address = GetAddress(array);
// Compute the address that the dummy object would have
// if it's stored after the array
var dummyObjectAddress = address
+ 4 /* MT pointer of the array */
+ 4 /* length of the array */
+ sizeof(double) * array.Length /* content of the array */
+ 4 /* Header of dummy object */;
if (*(nint*)dummyObjectAddress == objectMT)
{
object dummyObject = *(object*)&dummyObjectAddress;
Console.WriteLine($"Found dummy object AFTER the array: {dummyObject}");
}
else
{
// The dummy object wasn't found after the array, check before
dummyObjectAddress = address - 12;
if (*(nint*)dummyObjectAddress == objectMT)
{
object dummyObject = *(object*)&dummyObjectAddress;
Console.WriteLine($"Found dummy object BEFORE the array: {dummyObject}");
}
else
{
Console.WriteLine("The dummy object wasn't found :(");
}
}
GC.KeepAlive(bag);
GC.KeepAlive(array);
}
And we call the method with both values:
static unsafe void Main()
{
Console.WriteLine("With aligned address");
FindDummyObject(true);
Console.WriteLine();
Console.WriteLine("With unaligned address");
FindDummyObject(false);
}
After execution, the result is:
With aligned address
Found dummy object BEFORE the array: System.Object
With unaligned address
Found dummy object AFTER the array: System.Object
Great!
Wait… Shouldn’t it be the opposite? Shouldn’t the dummy object be allocated after the array when the allocation pointer is aligned? It turns out that when assigning a new allocation context, the GC allocates a 12 bytes Free object at the beginning of it. Because of this, the alignment is actually inverted compared to what we expected (= if the allocation context was aligned, it will become unaligned when expanding it because of those 12 bytes added at the beginning).
Wrapping it up
That… was a lot of hours spent on a single tweet. Even then, there are plenty of approximations in this article, which reflects the complexity of memory management in .NET. If somebody can figure out why the allocator uses an instance of Object instead of Free, I’d love to hear about it.
