Pro .NET Memory Management 2nd Edition
Let’s take a short break from writing a GC, to talk about Pro .NET Memory Management 2nd Edition. I’m usually not one to self-promote, but I keep being asked when the book will be out, so clearly we haven’t communicated enough about it. Here we go.
The short version
Pro .NET Memory Management 2nd Edition is available, on Amazon and probably other stores. Written by Konrad Kokosa (sole author of the 1st edition), Christophe Nasarre, and myself.

If you’ve never heard of this book, it is a very extensive source of information about memory management in .NET. Ranging from general concepts (heap, stack, allocations) to advanced topics such as a very detailled description of the inner mechanisms of the .NET garbage collector. Documentation about the .NET GC is sparse, and the 1st edition quickly became the de-facto reference on the subject.
The 2nd edition is mostly a polished version of the 1st edition: better writing with fewer grammatical mistakes, some complex explanations rewritten for clarity, and plenty of mistakes fixed. Of course, there is also new content, focused around the new .NET features that became available since the 1st edition: regions, pinned object heap, NonGC heap, SuppressGCTransition, large pages, GCConserveMemory, DATAS, provisional mode, memory limits, and more.
If you’re hesitant about whether to buy the book, I prepared a simple flowchart for you:
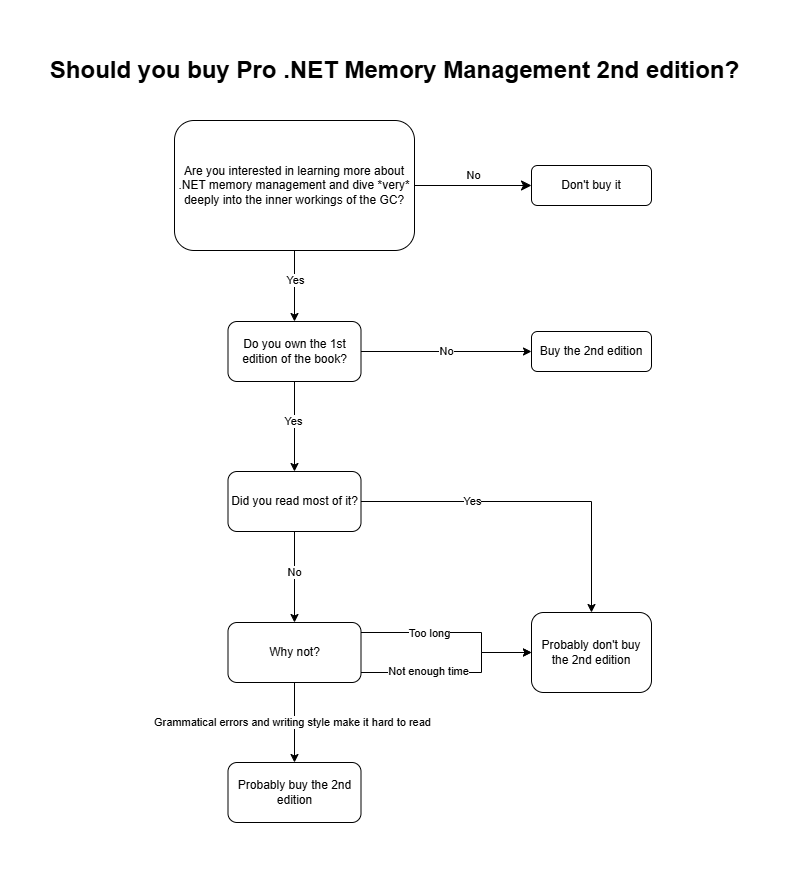
I should also add that, while this doesn’t engage the other authors, I fully support responsible piracy. If you are a student, or if you can’t afford the book: go ahead, I’ve pirated my fair share when I was younger. Just make sure to support authors when you can, or at least to contribute back to the .NET community somehow.
The long version
This part is going to be more opiniated, and also an excuse to address the first review posted on Amazon, which is well-argumented yet extremely negative.
The 2nd edition is the result of many hundreds of hours of work, across almost two years. Konrad contacted Christophe and myself back in January 2023, and after some hesitation (this was just one month after the birth of my son, so not a great time to write a book), I agreed to join the project. I had plenty of ideas for new content, but the first step was to read the 1st edition (I owned the book but I never tried reading it from start to finish, I was only referring to it for very specific topics). I quickly discovered that Apress did a terrible job reviewing the book, and it was extremely difficult to read. Of course, the topic itself is complex, but having to decipher the unusual sentence structures and the numerous grammatical mistakes added an extra mental strain. It became apparent that, before thinking of adding new content, we had to fix and polish the existing material.
It probably won’t come as a surprise, but it turns out that carefully reviewing 1000 pages of technical content is a lot of work. Especially when you also have to pause to verify every suspicious or obscure bit. And because the content of the book is truly unique, “verifying” doesn’t mean just “cross-referencing multiple sources” but really “reading the source code of the GC, tracking the original PRs, and building prototypes to validate my understanding”. The bottom-line is that reviewing the book took way, way longer than expected, leaving little time for new content. Which brings me to my biggest regret about the 2nd edition: it is really a fixed and refreshed version of the 1st edition rather than a new book. The new content is interesting, but not as extensive as I would have liked.
As a testament of the thoroughness of my work, I found no less than 6 bugs in the GC while writing the book:
With that in mind, I was extremely surprised to see the first review on Amazon. I’m posting it here for reference:
I approached Pro .NET Memory 2nd Edition with high expectations, hoping it would retain the advanced, in-depth technical content of the first edition while updating it to reflect the latest advancements in .NET. Unfortunately, this book is not an evolution of its predecessor but a complete departure—and a significant downgrade.
The first edition was a technical marvel. It didn’t just explain memory management; it delved into the underlying mechanics of computing itself, starting with foundational concepts like CPU caches, memory alignment, and hardware optimization. It tackled complex subjects like garbage collection internals, memory fragmentation, and strategies for maximizing performance in memory-intensive .NET applications. It was the kind of book that senior developers and architects could sink their teeth into, offering esoteric yet essential insights rarely found elsewhere.
This second edition, however, abandons that depth entirely. Rather than updating the advanced topics to reflect modern changes in .NET, it instead opts for a more generalized and shallow approach. The book focuses on basics—concepts like the generational garbage collector, simple memory leaks, and basic best practices—that are widely covered in beginner and intermediate-level programming books. For someone already familiar with .NET or the original edition, the content offers little value.
What makes this even more disappointing is that the structure of the original provided a perfect framework for improvement. The authors could have revisited and modernized the detailed explorations of low-level memory management, CPU interactions, and optimization strategies to align with today’s .NET runtime. Instead, they stripped away what made the first edition special and replaced it with material that feels rushed, superficial, and uninspired.
As I progressed through the book, I kept hoping for a chapter that would finally dive deep into the kind of advanced material the first edition offered. That moment never came. The book remained shallow from start to finish, leaving me frustrated and unsatisfied.
If you’re a seasoned developer looking for cutting-edge, low-level insights into .NET memory management, this book will leave you disappointed. I recommend sticking with the first edition, which, despite being outdated in some areas, remains a far superior resource for advanced developers. This second edition feels like a missed opportunity to expand and modernize an already brilliant work, and it’s unlikely to satisfy anyone who appreciated the original.
The author of this review visibly put a lot of thought into it, and seems very disappointed by the 2nd edition. All criticism is welcome, especially since the book is quite expensive, but it leaves me very confused. As I explained earlier, my biggest regret about the 2nd edition is that it’s very similar to the 1st edition. Calling it a “complete departure” makes no sense to me. We did cut some parts from it (all available as free PDFs on prodotnetmemory.com, in the “Parts removed from the first edition” section), either because they were obsolete (Pre .NET Core 3.0 Linux Tooling) or irrelevant to the topic (the history of memory management in computing, or the CLR hosting APIs). Apart from this, all the content from the 1st edition is still there, just polished and updated. All the low-level stuff, all the in-depth explanations, all the references to the GC source code… it’s all there. This review is so puzzling to me that it honestly makes me wonder if the reviewer is talking about the same book.
I was fully expecting to see people who bought both editions to complain about feeling ripped off: I genuinely don’t feel like the added content is worth the hefty $80 price tag, and I wish there was an “upgrade” option for people who already own the 1st edition. But calling the 2nd edition a “significant downgrade” makes no sense to me. Unfortunately, because this is the only review on Amazon right now, it’s going to significantly impact the perception of the book and probably scare off potential readers.
Closing thoughts
You might be surprised to discover that the 2nd edition is significantly smaller than the 1st edition: it went from 1000 pages to “just” 750.

This is not because of the removed content (which is compensated by the new content), but simply because we reduced the size of the font.

